
Privacy for Sale: How Your Identity is the Internet’s Hottest Commodity
A Brief Exercise in Self-Description
Please select the options that best apply to you:

Thank you for taking a moment to answer these questions. A decade ago, clicking through and submitting something like this would’ve been enough to help swing an election. But we will come back to that.
Before we do, let’s ask a different question.
What makes you you, and how much is that definition worth?
You might think that what makes you you-your thoughts, feelings, contradictions, values, anxieties–is something that is fundamentally unquantifiable. Something that is too fluid and too context-dependent ever to be reduced to numbers.
But the modern data economy disagrees. In fact, it has spent the past 15 years building an answer for it. While your inner life feels infinite to you, the system around you has figured out a way to translate your complexities into patterns, and finally came up with the conclusion:
There is a version of you that is quantifiable. Shockingly so.
The Datafied Self
In the digital age, you exist in two forms:
- The self: Complex and contextual
- The datafied self: Simplified and legible
The datafied version of you (as academics reference it) is the one that the world is increasingly interacting with. It is built from an accumulation of your patterns: your movements, interests, diet, activity patterns, social proximity, routines, and any deviations from them too. While this information may not seem significant at first glance—you might think, who cares that I usually wake up at 6 a.m. and get coffee from the café two blocks down—the inferred identity it produces is far more powerful than most people realize.
In a landmark 2013 study, researchers Michal Kosinski, David Stillwell, and Thore Graepel demonstrated that seemingly trivial digital traces (specifically Facebook Likes) are enough to accurately infer highly sensitive personal attributes.[1] Using data from over 58,000 users, their models predicted race with up to 95% accuracy (here, “accuracy” refers to the area under the ROC curve, typically used in predictive modeling frameworks), political affiliation with 85%, and sexual orientation with up to 88%, often without users ever explicitly disclosing those traits.
Even more unsettling, the system inferred psychological characteristics such as personality traits, with predictions for traits like openness, approaching the reliability of standard psychometric tests. The study highlights that privacy can no longer be protected by withholding information, because who you are can now be reconstructed from things that you never intended to reveal.
Since then, the way systems create inference has rapidly advanced.
Modern smartphones are dense sensor arrays. These days, your smartphone sensor data alone can even reveal shifts in conditions like depression, according to a 2021 article published in the Journal of Medical Internet Research.[2] And this is only one signal among many. Much of the most revealing tracking actually happens through data sources people rarely consider at all.
The following is just a few of these:
-
- Battery level, for instance, is routinely collected without permission. Low battery correlates strongly with urgency and impulsivity, making users more likely to accept surge pricing or make rushed decisions. These are patterns that ride-sharing apps have previously been accused of exploiting.
- Accelerometers, which typically require no user consent, can detect whether you are walking, running, driving, cycling, pacing, or lying down.
-
- Bluetooth beacons embedded in physical spaces allow retailers to map foot traffic, dwell time, and the likelihood of purchasing.
-
- Microphones can analyze ambient “silence patterns”, such as background noise, traffic density, wifi hum, or crowd acoustics. Apps can classify environments and infer location with surprising accuracy.
This is also why the most persistent fear—that phones are secretly listening—is often the wrong one.
Phones can listen in limited ways, but they rarely need to. Inference is easier to implement and is more scalable than “eavesdropping.” Thus, the monitoring most people experience is not overt listening but typically a covert pattern extraction by their devices.
Over time, these signals accumulate into models that help companies map your weekly routines, identify your anchor locations (home, workplace, partner’s home), estimate your commute patterns, and can even infer when you are bored, lonely, stressed, or susceptible to impulse decisions.
From these behaviors, systems are able to infer attributes you never explicitly disclosed, such as political ideology, relationship stability, sexual orientation, pregnancy status, likelihood of future illness, financial stress, susceptibility to persuasion, addiction risk, or whether you are planning to vote.
This is the datafied self: a compressed, predictive replica of you. Which then raises another question: If your data is a commodity, how much does it go for on the open market?
The Price of a Person in the Data Economy
Before we answer that previous question, let’s think about the questionnaire from the beginning of this article. Chances are, you didn’t stop to wonder why those questions were there; you just answered them. That’s a normal response.
It is exactly this behavior that makes these questionnaires useful in the first place. Those questions were not invented for this article; they come from the OCEAN (Big Five) personality framework used by Cambridge Analytica and researchers at the University of Cambridge’s Psychometrics Centre.
The original quiz had the following premise: that a number of self-reported statements combined with behavioral data could be used to model personality, and, by extension, be used to influence behavior. That premise turned out to be correct.
From Quiz Answers to Political Targeting
In 2014, a Facebook app called “This is your digital life” invited users to take a personality quiz. Around 270,000 people did. But because of Facebook’s API design at the time, the app also collected data from users’ friends (without their knowledge or consent), ultimately harvesting information from about 87 million people.
That data was then transferred to Cambridge Analytica, a political consulting firm that combined quiz responses with Facebook Likes, social graphs, voter rolls, and consumer data to build psychographic profiles.
This is important, as the firm worked on high-profile political campaigns, including the 2016 U.S. presidential election and the UK Brexit referendum. The resulting models they created based on the data were used to deliver highly targeted political messages tailored to voters’ inferred psychological traits. Whether Cambridge Analytica alone “swung” those elections remains debated. What is not debated is that personality could be inferred cheaply at scale, and then weaponized for persuasion.
How Much Did Cambridge Analytica Pay per Person?
Here’s the part that tends to surprise people. Cambridge Analytica reportedly paid less than $1 per person to acquire access to these profiles, as part of a broader contract costing under $1 million, while obtaining tens of millions of data records. In other words, the psychological modeling that caused global outrage was built on data that was, per person, incredibly cheap.
Outside of political campaigns, the same logic drives the commercial data economy, and the prices are often even lower.
What Your Profile Is Worth on the Open Market
Individually? Your profile might be worthless – often just a few cents.
But as part of a mass-scale dataset? It supports an industry that is worth hundreds of billions of dollars.
Within the commercial data industry, value emerges from scale, and inherently, scale collapses individual value. Data brokers routinely sell consumer profiles containing age, gender, income bracket, family status, interests, and inferred traits for as little as $0.01 to $0.40 per person, depending on how rich or specific the dataset is.
Mailing lists and behavioral segments are even cheaper when purchased at scale. Millions of records can be bought for just a few thousand dollars, placing the per-person price in the realm of cents. Meanwhile, your healthcare records might go for an average of $250, due to the highly sensitive information in them.
The Economics of Knowing You
To understand why so much of the internet feels invasive, you have to start seeing the tracking for what it is: a business model. Shoshana Zuboff famously defines surveillance capitalism as:
“The unilateral claiming of private human experience as free raw material for translation into behavioral data. These data are then computed and packaged as prediction products and sold into behavioral futures markets.”
In other words, the more accurately behavior can be anticipated, the more valuable the data becomes. Nowhere is this logic more visible than in advertising, specifically, online advertising.
In 2024, more than 65% of global advertising spend flowed through the internet. According to industry analysis, global ad spending is on track to exceed $1 trillion, driven almost entirely by digital channels, with online ads expected to account for 83% of all advertising revenue in 2025.
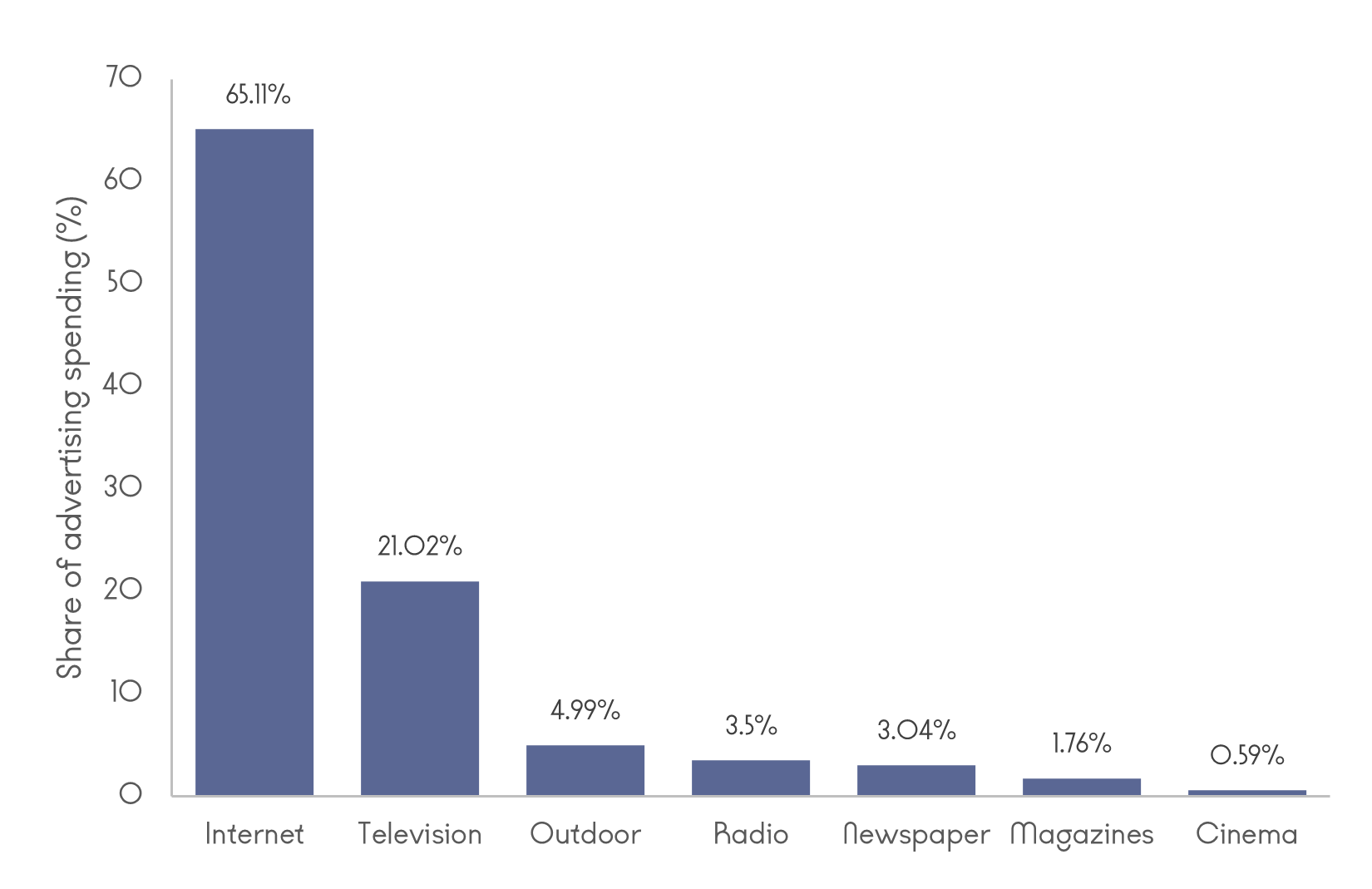
Tech giants like Meta’s financials make the dependency even more explicit, as its advertising has historically accounted for over 97% of its revenue, tying the company’s fortunes directly to how effectively it can extract and monetize user behavior.
But the advertising industry depends on a key component to obtain all this prediction data, and this is where data brokers enter the picture. These are the companies that aggregate, refine, infer, and resell personal data at an industrial scale, feeding advertisers, analytics firms, insurers, financial institutions, and increasingly AI systems. According to SNS Insider, the global data brokers market was valued at $257.2 billion in 2023 and is projected to reach $441.4 billion by 2032. Meanwhile, other sources forecast a market size as large as $616.541 billion by 2030.
While there are currently thousands of data broker companies in existence, key players in the industry include Oracle, which operates one of the world’s largest data clouds, Thomson Reuters, Equifax, and CoreLogic.
In summary, what ties advertising platforms and data brokers together is the same economic incentive, which is to reduce uncertainty about human behavior.
Structural Coercion & The Psychology of Consumer Behavior
At this point, a familiar objection tends to surface. If privacy matters so much and seems to be worth so much, then why don’t people protect it? Do they just not care?
While this question sounds reasonable, it is also a misleading one. It assumes that privacy decisions are made in a neutral environment by informed, rational individuals. In reality, privacy choices are made inside systems deliberately engineered to extract data, using psychological mechanisms that exploit how humans actually think and behave.
Why Privacy Decisions Are Systematically Skewed
Decades of research in behavioral economics and psychology show that people are not well-equipped to manage abstract, delayed, or probabilistic harms, especially when immediate rewards are offered in return.
Acquisti et al. describe this mismatch in their work on the economics of privacy.[3] They show that individuals routinely trade away personal data because the benefits of the disclosure are immediate, while the costs are often delayed and unknown. Even highly educated users dramatically underestimate the scope and downstream use of their data.
To make matters more complicated, platforms offer what looks like control: toggles, sliders, settings pages, and cookie banners. Research by Kitkowska and colleagues details how these privacy controls often create an illusion of agency, making people more comfortable sharing data precisely because they believe they are in control.[4]
Kitkowska’s work also documents how visual hierarchy, defaults, framing, and “confirmshaming” nudge users toward accepting tracking. “Accept all” buttons are large and brightly colored. “Reject” options are hidden behind multiple clicks or ambiguous language. Warnings are often framed as an inconvenience. These designs exploit the fact that humans rely heavily on System 1 type thinking (the fast, automatic, intuitive response) when navigating interfaces, often leading to option selection measured by what is most convenient.
This way, people are navigating an environment that was designed for them to fail. Often, they do not even realise the consequences of their clicks.
Privacy Protection: The Opposite Side of the Data Economy
For decades, there has been a particular refrain among people who claim not to care about privacy: “I’m not interesting enough for anyone to monitor.” It is a logical fallacy rooted in an outdated surveillance model, one where only influential figures were considered worth watching.
However, this assumption is starting to crack.
We explored this and similar beliefs more in depth in a recent Arcanum Ventures Boom Room: Spaces discussion, “Is Privacy Crypto’s New Narrative?”, now available on X and Spotify. In the conversation, a panel of privacy tech founders and technical experts discussed some of the biggest misconceptions in digital privacy, and why more and more people are beginning to question the systems that quietly shape their digital lives.
In the ad-tech world, everyone is worth watching. And as awareness of this has grown, a counter-market has emerged.
While one side of the economy continues to extract personal data for profit, the other side sells tools designed to limit that extraction. In effect, privacy and data protection tools have grown into a distinct economic segment.
The broader data privacy software market, which includes tools for compliance, governance, and consent management, is expanding swiftly. Analysts estimate that it could be valued at more than $20 billion by the early 2030s, driven by corporate risk management and the rising cost of breaches.
Meanwhile, narrower segments such as privacy management software are projected to grow from mid-single-digit billions in 2025 to nearly $30 billion by 2030.
Alongside enterprise privacy software are consumer-facing tools. These include VPNs, encrypted communications, and other privacy-enhancing services. As governments around the world move towards more ID-restricted forms of online access, the demand for tools that promise anonymity has rapidly accelerated.
The VPN market alone has ballooned into the tens of billions of dollars worldwide. Estimates suggest it could exceed $150 billion by 2030-2035, reflecting rising demand for encrypted connectivity in an increasingly monitored digital environment. As these services are becoming increasingly more elaborate, some VPN providers go as far as accepting cash sent by mail, allowing users to sign up without tying the service to a name.
While the pushback against online tracking has driven meaningful innovation, the unfortunate side of all of this is that privacy has become a commodity, and like any commodity, it comes with a price. Privacy, once assumed to be a default human condition, has become a premium status good reserved for those who can afford it.
Why Privacy’s Survival Depends on the Systems We Build Next
A decade of “free” apps has normalized surveillance as the default business model, and companies are still rewarded for collecting as much data as possible. Meanwhile, accountability lags behind, buried in rules most users neither see nor understand.
The Regulatory Gap
Despite the scale and sensitivity of the data involved, regulation remains patchy and reactive in nature. In the United States, there is no comprehensive federal law governing data brokers. Instead, oversight is fragmented across sector-specific statutes like HIPAA, FCRA, and COPPA, which leave large portions of the data economy untouched. As a 2024 report by Kanwal and Walby notes, most data brokers are under no obligation to verify accuracy, disclose data sources, or inform individuals that profiling is taking place.[5]
Some jurisdictions offer glimpses of what stronger governance could look like. The European Union’s GDPR introduces principles of data minimization (meaning that brokers only gather data that is truly essential) and meaningful consent. California’s CCPA and Vermont’s data broker registry represent early attempts to impose transparency and accountability. But even these frameworks struggle to keep pace with an industry built on resale and cross-border data flows.
What Moving Forward Requires
If privacy is to survive as more than a lifestyle choice or luxury subscription, it will require structural change at multiple levels:
- Clear legal definitions of data brokers, with mandatory registration, disclosure of data sources, and auditability
- Limits on data resale and retention, particularly for sensitive inferred attributes
- Meaningful enforcement mechanisms, including penalties proportional to global revenue
- Restrictions on government procurement of brokered data, closing loopholes that bypass constitutional protections
- Data minimization by design, shifting incentives away from maximal extraction toward necessity and proportionality
Kanwal and Walby argue that self-regulation is not viable anymore. The data broker industry is already too deeply embedded in the circuits of advertising and finance. Consequently, data extraction will continue by default.
The question, then, is not whether tracking will continue (because it most likely will) but whether societies choose to impose the right policies and regulations in place.
So what Makes You You? And Who Owns That Answer?
At the beginning of this article, you were asked a few simple questions. Nothing you haven’t clicked through a hundred times before. Today, the most consequential questions about who you are are no longer asked explicitly.
Nevertheless, this does not mean that choice has disappeared. People still have a choice to be more conscious about the data they share. Awareness alone does not solve the problem, but it does shape demand for better systems, and the future of privacy depends on the systems we build and the regulatory frameworks we put in place.
Which brings us back to the question that really matters:
So what makes you you? And who owns that answer?

Continue the Conversation
If these questions are on your mind, you are not alone. At Arcanum Ventures, we spend a lot of time thinking about how privacy, blockchain, web3, frontier tech, and AI-driven systems work best in practice. We even put out privacy-focused content from time to time, such as this interview with Sean O’Brien from Ivy Cyber.
Whether you want to listen in or join as a speaker on a privacy-focused podcast/event panel, or you want to stay updated on all the latest in privacy, Arcanum Ventures has you covered.
Arcanum Ventures also advises founders and teams building in complex, high-stakes environments. We can help with privacy tech and Web3 to data infrastructure and token design. If you are building something and want a second set of experienced eyes, we want to work with you!
References
[1] Kosinski Michal, David Stillwell, Thore Graepel, “Private Traits and Attributes Are Predictable from Digital Records of Human Behavior”, Proceedings of the National Academy of Sciences, 110 (15), 5802–5805, 2013
[2] Meyerhoff Jonah et al., “Evaluation of Changes in Depression, Anxiety, and Social Anxiety Using Smartphone Sensor Features: Longitudinal Cohort Study”, Journal of Medical Internet Research, 23 (9), e22844, 2021
[3] Acquisti Alessandro, Curtis Taylor, Liad Wagman, “The Economics of Privacy”, Journal of Economic Literature, 54 (2), 442–492, 2016
[4] Kitkowska Agnieszka, Karen Renaud, “Privacy-Related Choice Architectures: What Do We Know?”, Journal of Consumer Psychology, 30 (4), 2020
[5] Kanwal Rahul, Kevin Walby, “Tracking the Surveillance and Information Practices of Data Brokers”, Centre for Access to Information and Justice, Winnipeg, 2024

Specialized tokenized instruments represent the next evolution in digital capital markets. Moving beyond…

In 2026, tech investing is no longer about chasing hype cycles. It is about identifying durable narratives…

Zack Shapiro of Rains Law breaks down the legal traps founders miss when launching a crypto token. From…